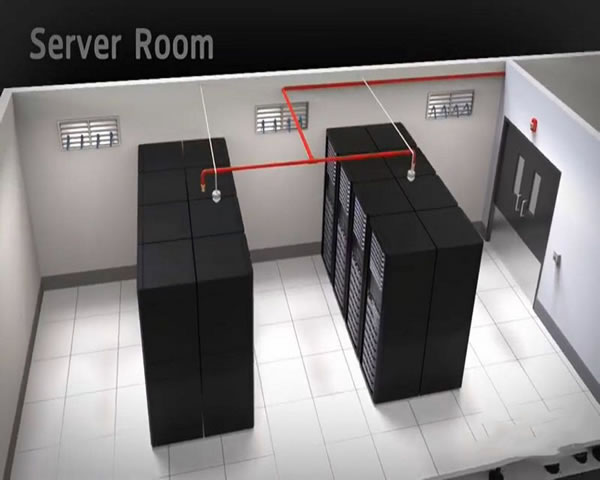
美国洛城高防服务器对突发流量洪峰的应急处理方案

问题1:面对突发流量洪峰,美国洛城高防服务器的首要应急响应流程是什么?
答:当出现突发流量洪峰时,首要是启动预定义的应急处理方案。流程一般为:1) 快速告警与流量确认;2) 流量分类与溯源;3) 启用临时防护策略(如ACL、速率限制、WAF规则);4) 动态调度CDN与清洗节点;5) 监控与迭代调整。对位于美国洛杉矶的洛城高防服务器而言,时间窗口尤为关键,通常要求在数分钟内完成初步隔离并在30分钟内实现流量清洗或切换。
检测与告警要点
答:必须依赖多维监控(网络层、应用层、日志行为)并配置阈值告警。结合Netflow、SYN/ACK比率、异常请求路径与UA指纹来判断是否为DDoS或业务突增。告警应通知值班工程师并自动触发预案脚本。
为什么要快速分类
答:区分合法流量与恶意流量可以避免误杀正常用户,提升响应效率。对于洛城高防服务器,分类策略通常根据源IP地理位置、请求频次、会话深度及HTTPS握手完整性来做判定。
小提示
答:预先准备好能够自动化下发的黑白名单与WAF策略模板,能将响应时间缩短至少50%。
问题2:如何快速识别洪峰的来源与攻击类型?
答:识别来源与类型需结合网络流量特征和应用层行为。常见的分辨方法包括:SYN/UDP泛洪通过包大小与端口分布识别,HTTP洪泛通过请求URI/Headers分析,慢速攻击通过连接时长与并发数分析。利用流量采样(sFlow)、PCAP抓包和日志聚合(ELK、Graylog)可快速定位可疑源。
溯源工具与指标
答:关键工具为:流量分析器、异常路由表、路由AS路径查询与ISP协作。关键指标包括PPS(包每秒)、BPS(比特每秒)、异常连接率、重复请求率和地理/ASN分布。
跨域联合溯源
答:对于复杂攻击,需与上游骨干ISP、CDN与云清洗服务商共享Netflow/PCAP证据,协同在上游进行黑洞过滤或流量清洗,这是应对大规模洪峰的常见做法。
注意事项
答:溯源速度决定处置效果,日志保留策略要覆盖攻击前后时间段,且时间同步(NTP)要准确,便于关联分析。
问题3:有哪些即时缓解措施可在洛城高防服务器上快速部署?
答:常见且高效的即时缓解措施包括:1) 启用WAF规则并进行精细化拦截;2) 对异常IP实施速率限制或临时封禁;3) 使用高防CDN或云清洗将流量导向清洗节点;4) 在路由器上配置ACL或黑洞路由以丢弃攻击流量;5) 启动流量降级策略保护核心业务接口。
技术实现示例
答:在洛杉矶机房,可通过BGP社区标记将流量引导到清洗中心,或在边缘NGINX/LB上动态下发限速规则。对于应用层攻击,可配置WAF正则与挑战(如Captcha、JS挑战)以阻挡自动化请求。
权衡误伤与持续性
答:防护策略需平衡误伤率与减轻效果;初期采取温和策略并快速观测效果,必要时升级为更严格的封堵。长期攻击需结合清洗与源头治理。
运营协同
答:运营与客服需同步告知用户临时限流或验证码策略,防止用户投诉升级影响业务声誉。
问题4:在突发洪峰下,如何完成资源扩容与故障切换以保证可用性?
答:资源扩容与切换包含水平扩容、跨机房切换和读写分离三大策略。优先使用自动扩容的云模型或弹性LB,将非核心流量迁移至备用机房或CDN。对于洛城高防服务器,应提前准备跨区域备份与健康检查脚本,确保在本地不可用时能在数分钟内切换到纽约或其它近区域节点。
扩容步骤
答:1) 启用弹性实例或容器组;2) 扩展负载均衡池并更新DNS或BGP路由;3) 在扩容同时同步会话/缓存数据(Redis/Session共享或粘滞会话降级);4) 逐步转移流量并监控错误率与延迟。
冷备与热备策略
答:热备能提供毫秒级切换,但成本高;冷备成本低但切换慢。对关键业务建议采用热备结合云清洗的混合方案,使应急处理方案既高效又经济。
DNS与BGP切换注意
答:DNS切换受TTL限制,BGP切换更实时。建议与ISP协商BGP快速切换策略并保留低TTL的DNS配置作为辅助。
问题5:事后如何复盘与优化,防止再次发生类似洪峰影响?
答:事后复盘包含事件回顾、根因分析、策略更新与演练四部分。收集攻击流量样本、告警记录与处理日志,评估各防护环节的响应时间与误伤率,补齐监控盲区并更新WAF规则与黑白名单。
改进清单
答:建议项包括:建立更精细的流量基线并采用机器学习异常检测;完善自动化编排(Playbook)与脚本库;扩展与ISP和云清洗厂商的SLA;定期进行模拟洪峰演练。
指标与KPI
答:制定关键KPI如MTTI(平均检测时间)、MTTR(平均恢复时间)、误伤率和可用性目标(如99.95%)。以数据驱动持续改进。
法律与合规
答:在复盘中审查是否涉及跨国溯源与证据保全问题,必要时与法务和ISP配合进行取证与举报。
-
媒体流量场景中cera美国高防服务器负载均衡配置要点
1. 概述与准备工作 1) 明确目标:对媒体(HTTP视频、RTMP、RTP/RTSP、QUIC)流量做高可用与高防护的负载均衡。2) 准备资源:至少两台或多台cera美国高防后端节点、1~2台负载均衡节点(可使用HAProxy/Nginx/LVS)、公网高防IP或BGP Anycast。3) 工具:ssh、iptables/nft、certb2026年4月24日 -

云速美国高防服务器提供专业网络保护
云速美国高防服务器提供专业网络保护 云速美国高防服务器是一家专业提供网络安全解决方案的公司,致力于为用户提供高质量的服务器租用服务。公司拥有先进的技术设备和专业的团队,能够为客户提供可靠的网络保护服务。 云速美国高防服务器提供专业的网络保护服务,能够有效防御各种网络攻击,保障用户的网络安全。公司拥有高性能的防火墙系统和DDoS2025年5月20日 -

美国G口高防服务器:保障您的网站安全。
美国G口高防服务器:保障您的网站安全。 body { font-family: Arial, sans-serif; margin: 20px; } h1 { text-align: center; } h2 { margin-top: 30px; } p { margi2025年4月28日 -

建站必备的美国高防服务器推荐与使用技巧
在当今互联网环境中,网站的安全性与稳定性显得尤为重要。选择一款合适的美国高防服务器不仅能够有效抵御网络攻击,还能提升网站的访问速度和用户体验。本文将为您推荐几款优秀的高防服务器,并分享使用技巧,帮助您更好地进行建站。 美国高防服务器有哪些品牌推荐? 市场上有许多知名的美国高防服务器提供商,它们各自的特点和优势也各不相同。以下是一些推荐的品牌:2025年8月5日 -

高防服务器帽子云的技术优势与应用场景
高防服务器帽子云的技术优势与应用场景 在当今互联网快速发展的时代,网络安全问题愈发严重,各类攻击层出不穷,尤其是DDoS攻击对企业的威胁更是巨大。为了保护企业的核心资产,很多企业开始选择使用高防服务器,而其中的帽子云更是以其独特的技术优势赢得了市场的青睐。本文将深入探讨高防服务器帽子云的技术优势与应用场景。 以下是帽子云的三大精华:2026年2月16日 -

美国CERA高防服务器:安全保障的最佳选择
美国CERA高防服务器:安全保障的最佳选择 CERA高防服务器是一种拥有强大防御能力的服务器,其设计目的是为了保护用户的数据安全,预防各种网络攻击。 在当今数字化时代,网络攻击层出不穷,威胁着个人和企业的信息安全。传统服务器往往无法有效抵御这些攻击,因此高防服务器的出现成2025年4月12日 -

免实名的美国高防服务器有哪些优势和劣势
免实名的美国高防服务器是近年来越来越受到关注的网络服务,尤其是在需要保护网站安全和隐私的情况下。以下是关于这一主题的五个常见问题及其解答。 问题一:什么是免实名的美国高防服务器? 免实名的美国高防服务器指的是在购买服务器时,无需提供个人真实身份信息的服务器。这种服务器通常位于美国,能够为用户提供高防护能力,抵御DDoS攻击等网络威胁。由于不需2025年8月15日 -
美国高防服务器问答解答常见疑问与难点
1. 什么是美国高防服务器? 美国高防服务器是一种专为抵御网络攻击(如DDoS攻击)而设计的服务器。它具备强大的防护能力,能够有效保护网站和应用免受恶意流量的影响。 高防服务器通常配备高性能的硬件和先进的防御技术,确保在遭受攻击时仍能保持正常运行。其主要功能包括流量清洗、攻击识别和自动应对策略等。 在选择高防服务器时,需要考虑多个因素,包括服2025年8月30日 -

美国高防服务器测评揭示性能与稳定性的真实表现
问题一:什么是高防服务器? 高防服务器是一种专门为抵御网络攻击而设计的服务器,特别是针对DDoS(分布式拒绝服务)攻击的防护。它通常配备强大的硬件资源和先进的防护技术,能够在攻击发生时保持网站或应用的正常运行。高防服务器的核心优势在于其能够有效过滤恶意流量,确保用户的合法访问不受影响。 问题二:美国高防服务器的性能如何? 美国高防服务器的性能通常非2025年10月13日