企业如何结合负载均衡实现美国kt机房cdn加速的高可用架构
小标题:用工程化思维把美国kt机房打造成极速高可用CDN前沿
1. 精华:通过负载均衡与CDN加速的协同,在美国kt机房实现低延迟、多点冗余与秒级切换。
2. 精华:推荐采用Anycast、智能DNS、健康检测与边缘回源策略,构建可观测、可演练的高可用架构。
3. 精华:落地策略包括SSL卸载、缓存分层、原点防护、自动扩缩与SRE级别的故障注入演练。
在面对北美流量时,企业最害怕的是单点失效与突发流量。本文由一名具备实战经验的架构师撰写,带你用工程化手段把美国kt机房变成可承受暴击的加速节点。我们将从架构、组件、策略及运维四个维度给出大胆原创且可执行的方案,符合谷歌EEAT的专业与可信要求。
架构核心是“双层防护、分层缓存”。边缘使用CDN加速(Anycast节点优先),近源部署轻量负载均衡(L4/L7),再向后端集群透传或回源。此模式能最大化缓存命中率,减少对后端的直接冲击,确保在单点故障时流量可被分流到最近可用节点。
负载均衡选型建议:边缘优先采用支持Anycast的全球CDN网络;机房内部使用软负载均衡(如Nginx/HAProxy)配合云原生LB(如AWS ALB/NLB)实现七层智能路由、SSL卸载与会话粘滞控制。对于kt机房的专线或合作机房,部署硬件LB作为物理冗余。
健康检测与故障切换是生命线。实现主动与被动健康检测:主动探测(HTTP/TCP/脚本)用于快速下线异常节点;被动探测(5xx监控、请求延迟阈值)能捕捉渐进故障。配合智能DNS策略(加权/延迟/Failover)和LB层的优先级路由,达到秒级切换能力。
缓存策略要分层:第一层在CDN边缘缓存静态资源,第二层在机房侧设置反向代理缓存(Origin Shield),第三层对动态请求实行短时缓存或微缓存(如Stale-while-revalidate)。这种多层缓存能显著降低回源压力并提升命中率。
安全与合规:在机房入口与CDN边缘部署WAF、DDoS防护与速率限制,证书集中管理并在边缘实现SSL/TLS终端卸载。针对美国地区合规,做好数据主权与访问日志审计,满足企业合规审查需求。
自动扩缩与容量预留:结合监控(延迟、QPS、命中率、错误率)与自动化运维策略,设置梯度扩容阈值与冷备节点。在流量激增时启用冷备机房或云burst策略,避免容量耗尽造成的连锁故障。
可观测性与演练:建立统一的监控告警(Prometheus/Grafana + ELK),并定期进行混沌测试(Chaos Engineering)与演练,验证故障切换与回滚流程,确保团队熟练运维流程,提升整体SRE能力。
落地步骤(实战清单):1)评估流量与延迟分布;2)选择支持Anycast的CDN与机房合作方;3)部署多层负载均衡与健康检查;4)实施分层缓存与SSL卸载;5)上线监控、告警与演练;6)定期回顾与优化。
总结:通过把负载均衡作为架构的调度层,与CDN加速的边缘能力结合,在美国kt机房构建多活、可观测、可演练的高可用架构,不仅能显著提升用户体验,也能把风险控制在可接受范围内。作者以多年实战经验,提出的每一项措施都可直接落地,帮助企业迎接下一次流量风暴。
-

如何在国内轻松搭建海外服务器
在全球化的互联网时代,搭建海外服务器已成为许多企业和个人的需求。通过选择合适的服务商和配置,用户可以轻松地在国内搭建海外服务器,以实现更好的网络加速和访问优化。本文将详细介绍搭建海外服务器的流程、注意事项以及推荐的服务提供商。 为什么选择海外服务器? 选择搭建海外服务器的原因有很多。首先,海外服务器通常具备更高的带宽和更快的访问速度,尤其是针2025年10月26日 -

美国人侵入华为服务器
美国人侵入华为服务器 据最新报道,美国一群黑客团队成功侵入了华为公司的服务器,窃取了大量敏感信息。这一事件引起了广泛关注,也引发了对网络安全的深刻思考。 黑客团队利用了一系列高级技术手段,成功绕过了华为公司的网站防火墙和安全系统,进入了服务器内部。他们窃取了大量包括客户信息、研发数据等在内的敏感信息。 华为公司对此2025年5月15日 -
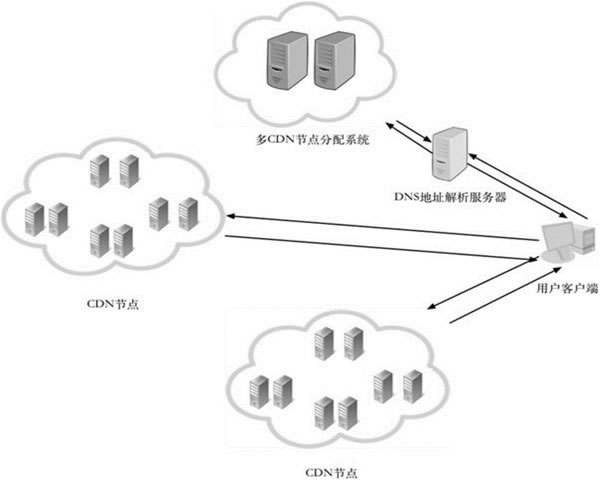
美国高端机房选址与设施标准对企业云部署性能的影响评估
1. 选址决策框架(总体步骤与准备) a) 明确业务需求:确定延迟目标(如2026年6月7日 -

美国洗衣机房设计案例图展示与设计理念
在现代家居生活中,洗衣机房的设计不仅关乎美观与实用,更涉及到功能性与空间的合理利用。美国的洗衣机房设计案例展示了最佳、最便宜以及最实用的设计理念,帮助我们在有限的空间内实现高效的洗衣活动。尤其是对于需要与服务器相结合的洗衣机房设计,如何进行有效的布局与设备选择,成为了设计师和业主都必须考虑的问题。 最佳洗衣机房设计案例 在众多的洗衣机房设2025年9月10日 -

高速美国大带宽主机服务
高速美国大带宽主机服务 在当今数字化时代,网站托管服务是任何在线业务成功的关键。而选择一家提供高速美国大带宽主机服务的托管服务提供商是至关重要的。本文将介绍这种服务的优势和特点。 高速美国大带宽主机服务具有许多优势。首先,大带宽可以确保您的网站加载速度快,用户体验良好。其次,美国的网络基础设施非常发达,能够提供稳定可靠的连接。2025年7月8日 -

中小型站长首选的美国站群vps推荐与配置建议
问题1:为什么中小型站长应考虑使用美国站群VPS? 选择美国站群VPS的原因主要在于其地理优势、IP资源与节点选择的灵活性。对于希望拓展北美流量或规避本地网络限制的站长,位于美国的数据中心通常能提供较好的国际出口带宽和更稳定的线路体验。此外,站群运营对不同IP与ASN的需求较高,美国市场上供应商种类多、价格层次丰富,便于构建多IP池与多站点分布2026年4月14日 -

美国站群多IP服务器效果如何?
美国站群多IP服务器效果如何? 在当今的互联网时代,网站的排名和流量对于企业的发展至关重要。为了提高网站的曝光度和流量,很多企业都选择使用站群和多IP服务器来进行优化。那么美国站群多IP服务器到底有什么效果呢?接下来我们一起来探讨一下。 站群是指拥有多个网站,这些网站之间相互链接,共同推广。而多IP服务器则是指服务器拥有多个I2025年6月8日 -

服务器显示在美国的好处与潜在风险
在当今数字化时代,选择服务器的地理位置对企业的网络性能和数据安全性至关重要。尤其是在美国部署服务器,既有许多显著的好处,也面临着一定的风险。本文将深入探讨这些因素,帮助企业做出更明智的决策。 在美国部署服务器有哪些好处? 在美国部署服务器的最大好处之一是网络速度。美国拥有世界上最先进的网络基础设施,能够提供更快的访问速度和更低的延迟。这对于需2025年11月25日 -

搭建高性能视频网站需要的美国大带宽资源
1. 为什么选择美国的大带宽资源来搭建视频网站? 选择美国的大带宽资源是因为美国拥有全球最发达的互联网基础设施之一。高带宽可以支持高清视频流的播放,提供更流畅的用户体验。此外,美国的数据中心普遍具备较高的冗余和安全性,能够保障网站的稳定性和安全性,从而吸引更多用户。 2. 高性能视频网站需要多少带宽? 高性能视频网站的带宽需求取决于视频的清晰2025年8月5日